

The new OpenMP 5.0 API released
OpenMP is probably the most used API to parallelize applications running on multicore processors and with the last update it is also GPU accelerators.
OpenMP is an application program interface that supports multi-platform shared memory multiprocessing programming in C, C++, and Fortran,on most platforms, instruction set architectures and operating systems, including Solaris, AIX, HP-UX, Linux, macOS, and Windows. It consists of a set of compiler directives, library routines, and environment variables that influence run-time behavior.
The latest OpenMP 5.0 API are released in November 2018 and they are probably the most important update to the framework since the inaugural release in 1997.
Some of the new features of the new API were under development for more than five years.
With OpenMP 5.0, the biggest change with regard to GPUs is support for unified shared memory between the GPU accelerators and the CPU hosts in a hybrid system. “You don’t have to transfer ownership of data any more, you can just access the CPU and GPU regions,” says Michael Klemm, who is chief executive officer for the OpenMP Architecture Review Board Consortium.
OpenMP implements the fork-join parallel design pattern: the master thread forks into a parallel region by forking a team of (Worker) parallel threads, then Team threads join with master at parallel region end.
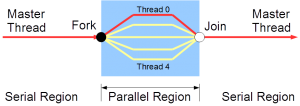
OpenMP Master Thread flow and Fork-Join Design Pattern
Simple OpenMP Parallel Threads example in C programming language
#include <stdio.h>
#include <omp.h>
int main(){
#pragma omp parallel
{
int testId = omp_get_thread_num();
int nThreads = omp_get_num_threads();
printf("Thread %d out of %d.\n", testId, nThreads);
for(int k=0; k<3; k++){
printf("Iteration number:%d\n",k);
}
}
printf("Returned to the Main Thread\n");
}
Download here official OpenMP 5.0 API Syntax Reference Guide
