

Big Data e Apache Hivemall: Machine Learning con SQL
Chiunque usi le tecniche di Machine Learning conosce molto bene la complessità di questo processo che richiede la conoscenza di linguaggi di programmazione, strutture matematiche, framework e algoritmi con un considerevole impegno soprattutto in termini di tempo.
Con Hivemall, Apache fornisce una libreria di machine learning scalabile realizzata come collection di User Defined Functions che permettono a chiunque abbia conoscenza SQL di utilizzare algoritmi di machine learning. Hivemall viene eseguito su un framework di processamento dati basato su Hadoop, un file system distribuito, con MapReduce come modello di processamento dati parallelo in questo ambiente. È possibile provare queste funzionalità in ambienti Apache Hive o Spark.
Come Google BigQuery ML, Apache Hivemall permette di applicare algoritmi di machine learning ai Big Data con delle serie di query. Queste soluzioni introducono un nuovo paradigma “machine learning in query language” ed essenzialmente hanno lo stesso approccio logico ma Hivemall è più flessibile in termini di piattaforme e algoritmi.
Diagramma Stack dell’ambiente Hivemall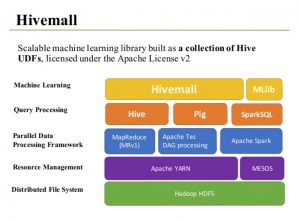
Usa queste istruzioni per provare Hivemall
Prerequisiti
- Hadoop v2.4.0 o successivo
- Hive v0.13 o successivo
- Java 7 o successivo
- hivemall-all-xxx.jar
- define-all.hive (scaricalo qui dalla pagina ufficiale di github)
Installazione
Aggiungi le seguenti righe al file $HOME/.hiverc
add jar /home/myui/tmp/hivemall-all-xxx.jar;
source /home/myui/tmp/define-all.hive;
Questo carica automaticamente tutte le funzioni Hivemall ogni volta che avvi una sessione Hive. Alternativamente, puoi caricarle solo quando ne hai bisogno.
$ hive
add jar /tmp/hivemall-all-xxx.jar;
source /tmp/define-all.hive;
Puoi avviare Hivemall anche su piattaforma Apache Spark e Pig.
Per le librerie Hivemall e documentazione vai al progetto ufficiale Apache a questo link
